Using Google bots as an attack vector


This article examines a highly original attack vector: using Google bots to perform attacks. It examines how search engines use bots to help index websites, explains how such attacks happen, and shows how to counter them. Code samples are included.

According to statistics, Google has a market share of more than 90% among search engines. Many users use their address bar as a Google search bar. With this continued market dominance, being visible on Google is crucial for websites. In this article, we analyze a study from F5 Labs which brings our attention to a new attack vector using Google’s crawling servers, also known as Google Bots. These servers gather content from the web to create the searchable index of websites from which Google’s search engine results are taken.
How search engines use bots to index websites
Each search engine has its unique set of algorithms, but they all work in a similar way: they visit a given website, look at the content and links they find (this is called crawling), and then grade and list the resources. After one of these bots finds your website, it will visit and index it.For a good ranking, you need to make sure that search engine bots can crawl your website without issues. Google specifically recommends that you avoid blocking search bots in order to achieve successful indexing. Attackers are aware of these permissions and have developed an interesting technique to exploit them: abusing Google bots.
The discovery of a Google bot attack
In 2001, Michal Zalewski wrote in Phrak magazine about this trick. He also highlighted how difficult it is to prevent it. Just how difficult became apparent a full 17 years later, when F5 Labs inspected the CroniX cryptominer. When F5 Labs researchers analyzed some malicious requests they had logged, they discovered that the requests originated from Google bots.Initially, the F5 Labs researchers assumed that an attacker had simply used the Google bot’s User-Agent header value. But when they investigated the source of the requests, they discovered that the requests were indeed sent from Google.There were different explanations for why Google servers would send these malicious requests. One of them would be that Google’s servers had been hacked. However, that idea was discarded quickly as it wasn’t likely. Instead, researchers focused on the scenario laid out by Michal Zalewski: that Google bots were abused in order to make them behave maliciously.
How did the Google bots turn evil?
Let’s take a look at how attackers can abuse Google bots in order to use them as a tool with malicious intent. First, let’s say your website contains the following link:<a href="http://victim-address.com/exploit-payload">malicious link<a>When Google bots encounter this URL, they’ll visit it in order to index it. The request that includes the payload will be made by a Google bot. This image illustrates what happens:
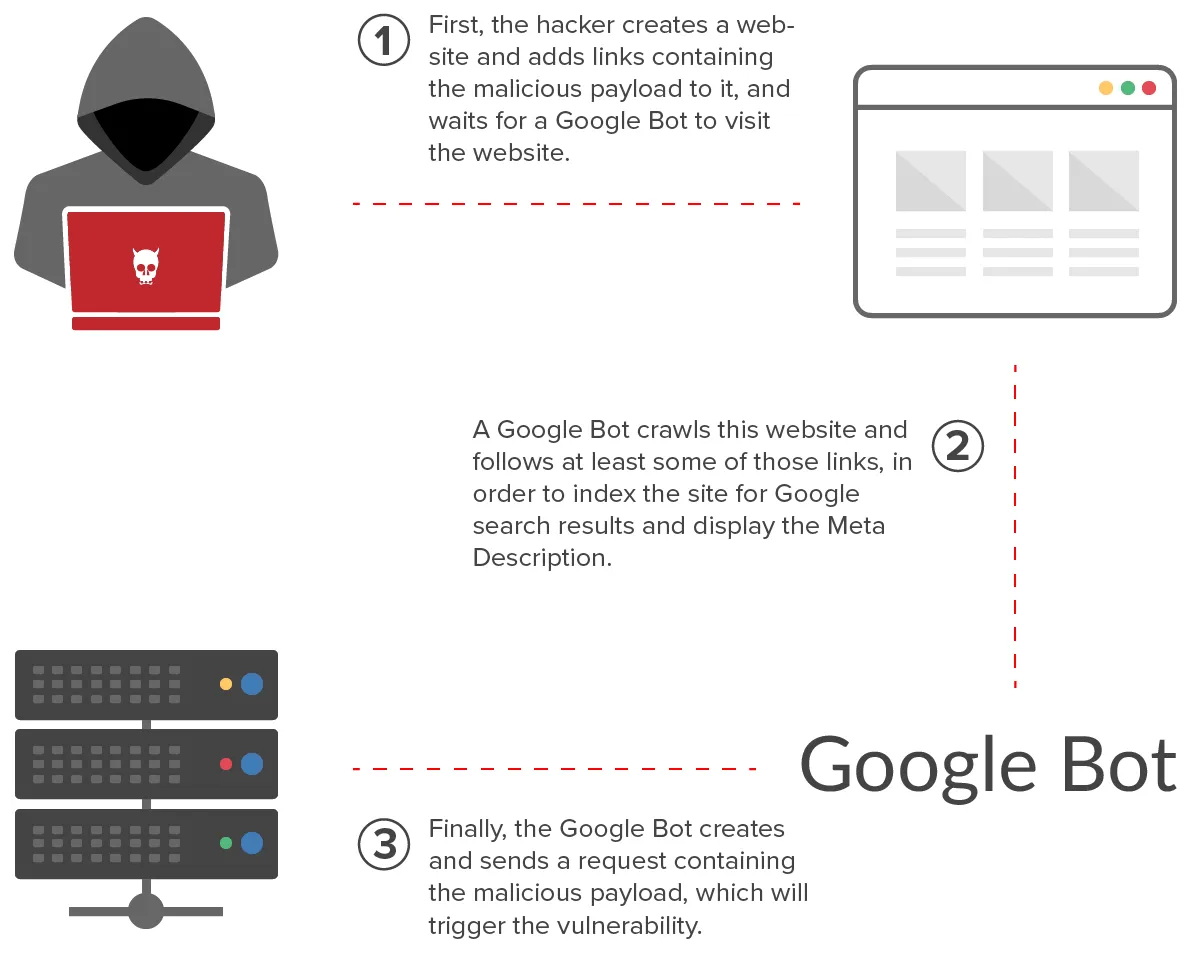
The experiment conducted to prove the attack
To verify the theory that a Google bot request could carry a malicious payload, the researchers conducted an experiment where they prepared two websites: one that acted as the attacker and one that acted as the target. The links that carried the payload were added to the attacker’s website and then sent to the target website.Once the researchers had set the necessary configurations for Google bots to browse the website, they simply waited for bot requests. When they analyzed the requests received, they found out that its was indeed requests from Google bot servers that were carrying the attack payload.
Limitations of the attack
This scenario is only possible in GET requests where the payload can be sent through the URL. Another limitation is that the attacker won’t be able to read the victim server’s response, so the attack is only practical if it’s possible to send the response out of band, like with a command injection or an SQL injection.
Combining Apache Struts RCE (CVE-2018-11776) with Google bots
Apache Struts is a Java-based framework released in 2001. The frequent discoveries of code evaluation vulnerabilities in the framework generated many discussions about its security. For example, the Equifax Breach that led to the loss of $439 million and the theft of a huge amount of personal data was the result of CVE-2017-5638 – a critical code execution vulnerability found in the Apache Struts framework.
A quick recap of Apache Struts Remote Code Evaluation (CVE-2018-11776)
Let’s recap on a vulnerability that could be exploited in pre-2018 Apache Struts versions. The CVE-2018-11776 vulnerability (discovered in August 2018) was perfect for a Google bot attack, since the payload issent through the URL. Not surprisingly, this was the vulnerability that CroniX abused.Here are two examples:
- The
helloin this URL is a namespace: http://www.example.com/hello/index.action. - Likewise, the
/that precedesindex.actionis considered to be a namespace: http://www.example.com//index.action.
When a namespace is not set, the configuration that leads to the vulnerability allows user-defined namespaces to be set from the path. In this situation, it’s possible to inject an OGNL (Object-Graph Navigation Language) expression. OGNL is an expression language in Java.Here is an example of a configuration that is vulnerable to CVE-2018-11776:<struts><constant name="struts.mapper.alwaysSelectFullNamespace" value="true" /><package name="default" extends="struts-default"><action name="help"> <result type="redirectAction"> <param name="actionName">date.action</param> </result></action>.....</struts>You can use the following sample payload to confirm the existence of CVE-2018-11776. If you open the URL http://your-struts-instance/${4*4}/help.action and you get redirected to http://your-struts-instance/16/date.action, you can confirm that the vulnerability exists.As mentioned before, this is the perfect context for a Google bot attack. As CroniX shows, attackers can go as far as spreading cryptomining malware using a combination of Apache Struts CVE-2018-11776 and Google bots.
Preventing Google bot attacks
At this point, the possibility of malicious links directed to your website from Google bots should make you question which third parties you can really trust. And yet blocking Google bot requests entirely is not an option, as it would negatively influence your position in Google search results. If Google bots cannot browse your website, this will pull down your ranking in the search results. So if your application detects malicious requests and blocks them, or even blocks the sending IP, attackers could use Google bot requests to send malicious payloads, which would result in blocked Google bots and therefore further damage your search result rankings.
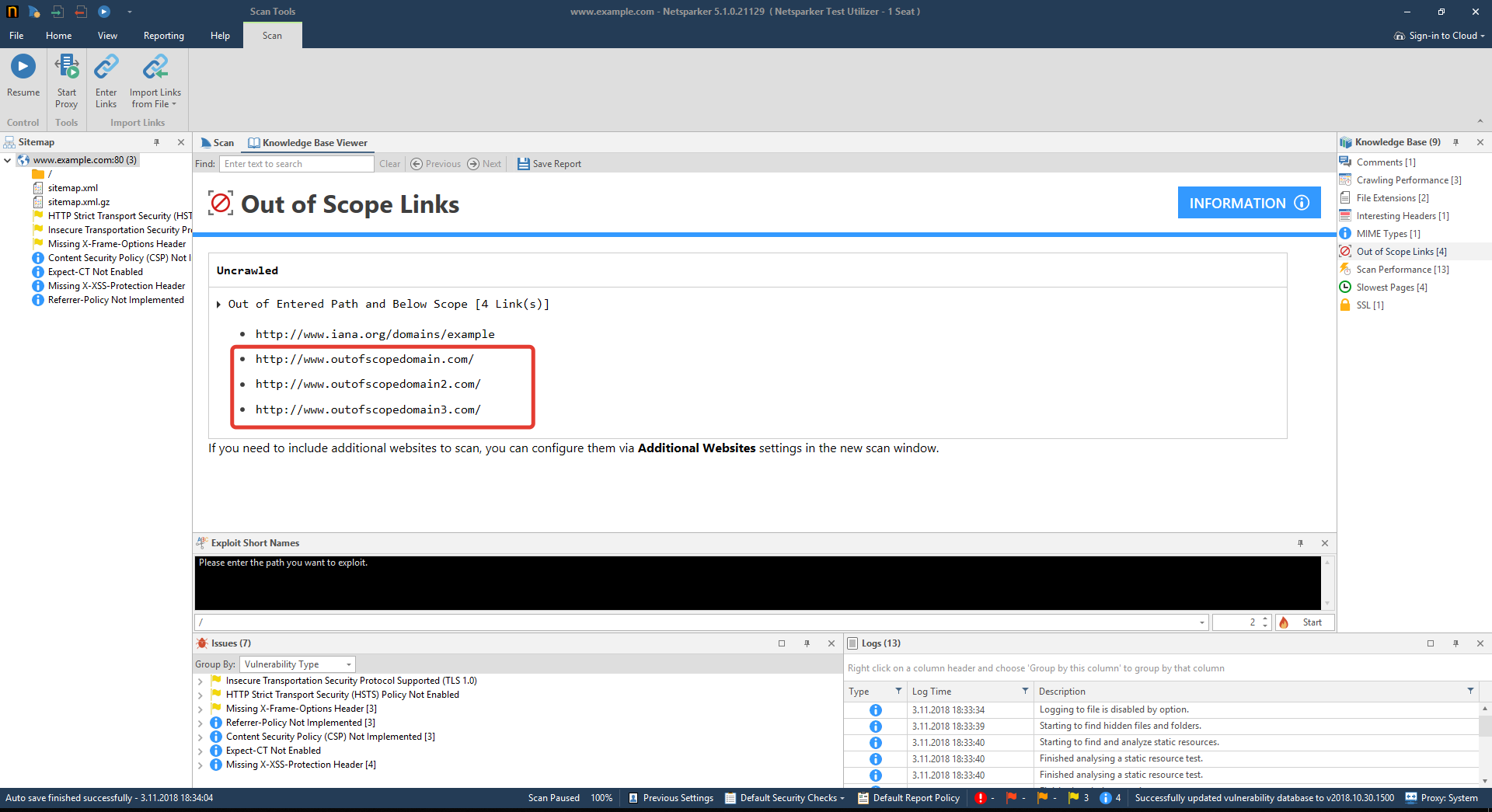
Control external connections on your website
Attackers can use their websites (or sites under their control) to conduct malicious activity using Google bots. They might also place links on a website in comments under blog posts.If you want an overview of the external links on your website, you can check the Out-of-Scope Links node in the Netsparker Knowledge Base following a scan.
Correctly handle links added by users
Even though it won’t prevent attackers from abusing Google bots to attack websites, you might still be able to prevent search engine ranking impact if you take certain precautions. For example, you can prevent search bots from following links using the rel attribute in combination with nofollow. This is how it’s done:<a rel="nofollow" href="http://www.functravel.com/">Cheap Flights</a>Due to the nofollow value of the rel attribute, the bots will not visit the link.Similarly, the meta tags you define between the <head></head> tags can help control the behavior of the search bots on all URLs found on the page.<meta name="googlebot" content="nofollow" /><meta name="robots" content="nofollow" />You can give these commands using the X-Robots-Tag response header, too:X-Robots-Tag: googlebot: nofollowNote that commands given with the X-Robots-Tag and meta tags apply to all internal and external links.
Further reading
Read more about the research on the Google bots attack in Abusing Googlebot Services to Deliver Crypto-Mining Malware.Article written by Netsparker security researchers:Ziyahan AlbenizUmran YildirimkayaSven Morgenroth
Frequently asked questions
Experience the future of AppSec
