How the BEAST attack works: Reading encrypted data without decryption
BEAST, or Browser Exploit Against SSL/TLS, was a man-in-the-middle attack that could expose information from an encrypted SSL/TLS 1.0 session. The attack exploited a known cipher suite vulnerability that was considered low-risk until a proof of concept arrived, prompting browser vendors and web server administrators to quickly move to TLS v1.1. This article shows how the BEAST attack worked, how a theoretical vulnerability became practically exploitable, and why modern browsers are no longer vulnerable.

The underlying vulnerability: Unsafe initialization vectors in TLS 1.0
The vulnerability in version 1.0 of the TLS (Transport Layer Security) protocol that was later exploited in the BEAST attack had been known since 2002 and fixed in the TLS 1.1 specification from 2006. It was considered impractical to exploit, as it required a huge number of attempts to discover even a single byte of information. Upgrading to 1.1 wasn’t considered a priority, so in 2011, most websites still used SSL or TLS 1.0—and when the proof of concept arrived, they were wide open to attack.
The BEAST attack exploited a vulnerability in the way the TLS 1.0 protocol generated initialization vectors for block ciphers in CBC mode (CVE-2011-3389). Combined with some clever manipulation of block boundaries, the flaw allowed a man-in-the-middle attacker sniffing encrypted traffic to discover small amounts of information without performing any decryption. Worse, the exploit worked regardless of the type or strength of the block cipher used.
Before diving into the attack proper, let’s start with some background information about symmetric cryptography using block ciphers.
Cryptography refresher: Block ciphers and initialization vectors
Whenever you connect to a website over HTTPS, your browser and the web server first have to decide how to encrypt your session. The negotiation and key exchange process is protected using asymmetric (public-key) cryptography, but all the data exchanged afterward is encrypted using much faster symmetric algorithms, usually block ciphers such as DES, 3DES, or AES. Block ciphers work by encrypting fixed-length blocks of data, and if the last block of a message is not completely filled, it is completed (padded) with random data.
Without additional steps, a block cipher would always generate the same ciphertext for the same data and key, making it vulnerable to chosen plaintext attacks. To avoid that, block ciphers are only used in specific modes of operation that do additional processing to increase security. The most common mode is Cipher Block Chaining (CBC), where each new block of plaintext (original message) is combined with the previous block of ciphertext (encrypted message). In this way, the value of each block depends on all the preceding blocks. But wait—the first block doesn’t have a preceding block, so what happens there?
In CBC mode, that first block is combined with an initialization vector (IV), which is a random block of “starter” data to make each message unique. The security of any block cipher in CBC mode depends entirely on the randomness of initialization vectors. And here’s the problem: in TLS 1.0, initialization vectors were not fully randomly generated. Instead of generating a new IV for each message, the protocol used the last block of ciphertext from the previous message as the new IV. This opened up a potential vulnerability because anyone who captured the encrypted data also got the initialization vectors. And because blocks were combined using a simple XOR, which is a reversible operation, knowing the initialization vectors could allow an attacker to discover information from encrypted messages.
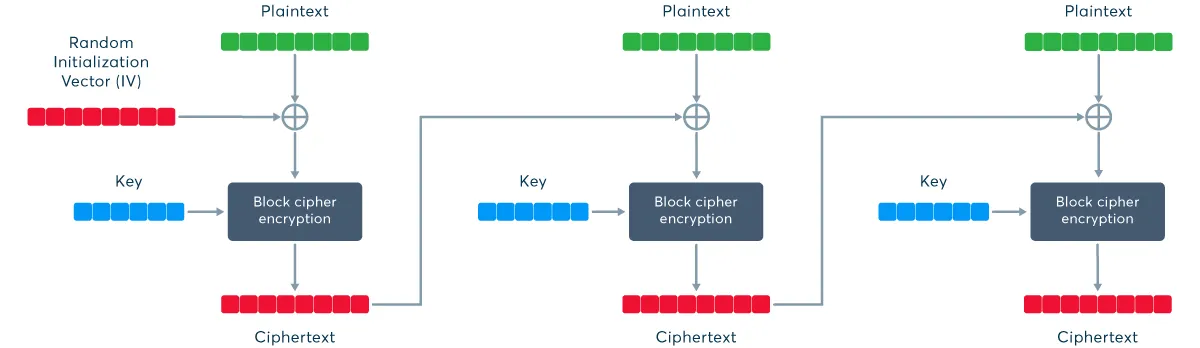
How it should work: Proper encryption using a block cipher in CBC mode
How to discover encrypted information without decrypting it
Let’s say we have a man-in-the-middle attacker who is sniffing TLS 1.0 traffic and can also inject data into it (maybe by running an evil public Wi-Fi hotspot). If the attacker knows what kind of data is being sent and where it is in the message, they can inject a specially crafted data block and examine the data stream to check if the encrypted version of that block is what they were expecting. If so, the injected guess was correct and the attacker has just discovered one block of the plaintext. If not, they can try guessing different values again and again—this is called a record splitting attack.
But what is that “specially crafted” data block? As we already know, to encrypt a data block in CBC mode, TLS 1.0 uses XOR to combine the plaintext block, the previous ciphertext block (which the attacker knows), and the initialization vector (which the attacker also knows from sniffing the preceding message). XOR is a reversible operation, allowing the attacker to mount a chosen plaintext attack by guessing a likely block of data, XOR-ing it with the IV and the preceding block of ciphertext, and injecting the result into the session.
Now for the “impractical” part. The attacker can only check if an entire block was guessed correctly. Block size varies depending on the cipher, but discovering an entire block by brute force checks would always require an impractically large number of attempts. For example, if you have 8-byte (64-bit) blocks with 256 possible values for each byte, the total number of combinations to check is 2568. Even assuming some smaller subset of characters, it’s still raised to the power of eight—far too many combinations to usefully check over a network. This is why the vulnerability was not considered a real threat until the first proof of concept surfaced.
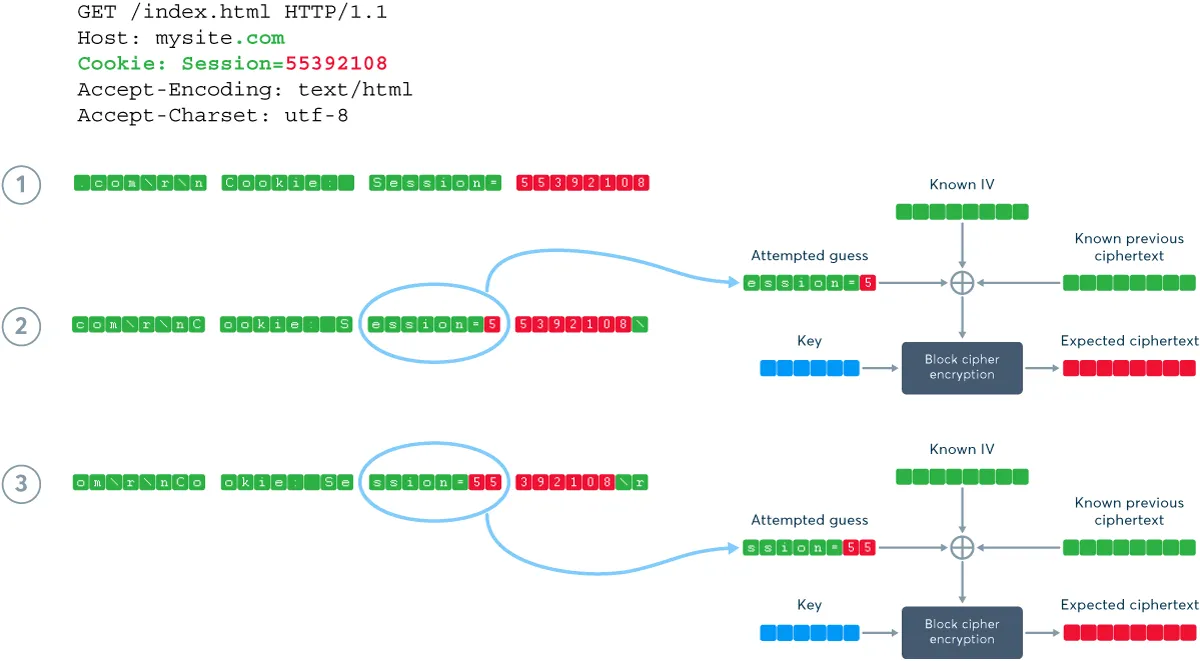
The underlying vulnerability: A record splitting attack against TLS 1.0
The BEAST exploit: Record splitting with a chosen boundary attack
In 2011, security researchers Thai Duong and Juliano Rizzo published the first proof of concept exploiting this vulnerability. By shifting cipher block boundaries to isolate a single byte at a time, they managed to dramatically reduce the number of attempts needed to guess a value. Instead of guessing the whole block, the attacker is now brute-forcing only one byte at a time, so guessing a 10-digit number would need just 10 guesses for each digit, no more than 100 attempts for the whole number in the worst case, and just 50 attempts on average.
Duong and Rizzo’s blockwise chosen boundary attack relies on the rigid structure and predictable content of HTTP packets, especially when they contain equally predictable HTML code. By carefully crafting HTTP requests, you can precisely control the location of cipher block boundaries to create a message where you know all the bytes except the targeted data (typically a session cookie or other authentication token). You then shift the block boundaries to obtain a block where exactly one byte is unknown, and that byte is discovered by exploiting the TLS 1.0 vulnerability. You then shift the block boundaries by one byte and repeat the whole process until all unknown bytes have been discovered.
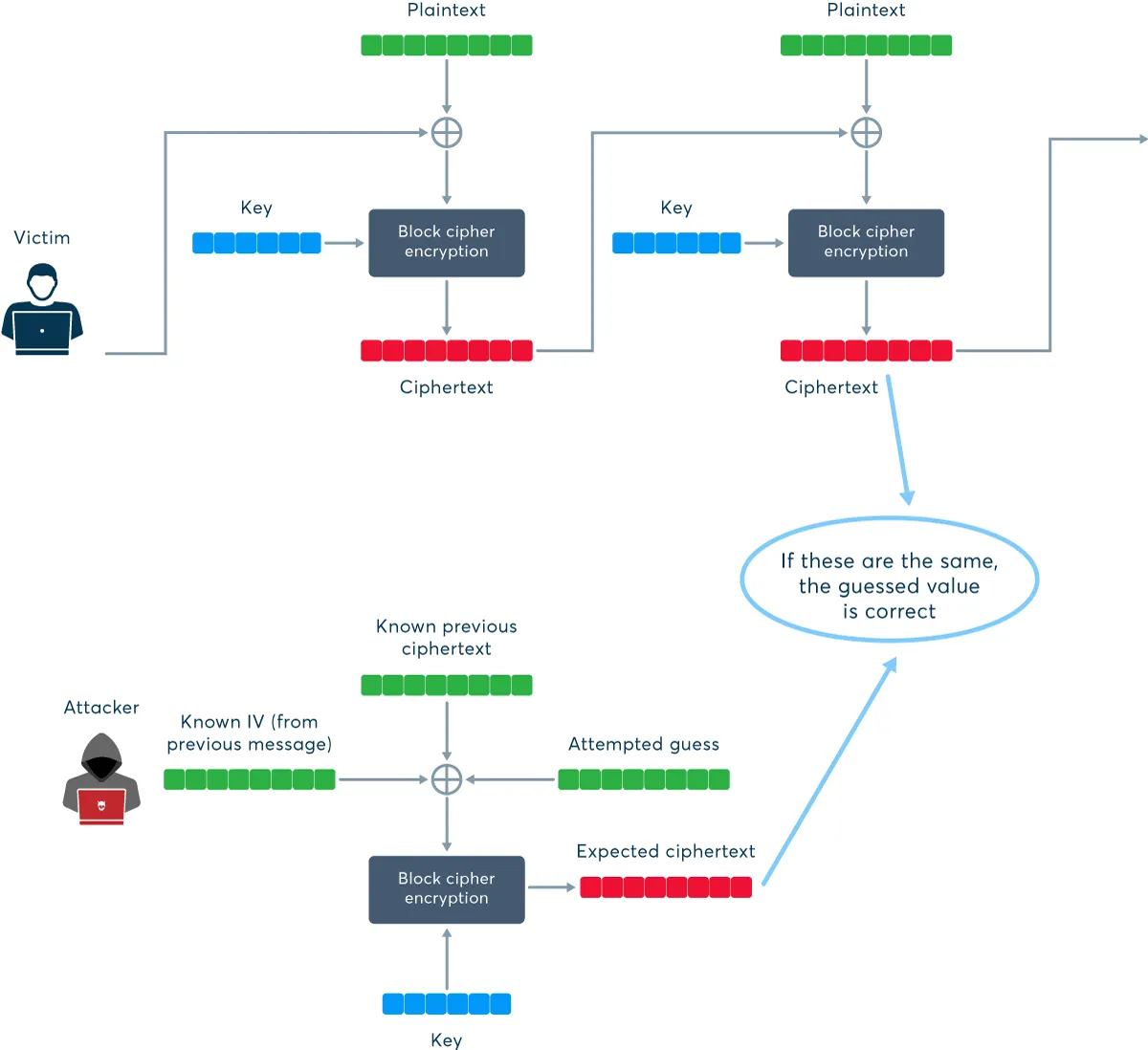
The BEAST exploit: A chosen boundary attack combined with record splitting
The attack was ingenious but not easy to perform. For one, it required an additional browser exploit to perform record splitting and inject arbitrary data into the HTTPS stream. In their proof of concept, Duong and Rizzo exploited a vulnerable Java applet running in the browser. Apart from the Java URLConnection API, the attack could also be mounted using JavaScript that called the HTML5 WebSocket API or even the Silverlight WebClient API. What’s more, injecting code into the session required a violation of the same-origin policy, making real-life exploitation that much harder.
The BEAST attack was limited to recovering short strings and still required a relatively large number of requests, but in specific situations, it could be practically used to read session cookies or login credentials, especially in the days before browser sandboxing. Take a feasible attack scenario where the user browses to some site that silently executes a malicious script. Without closing this site, the user then logs into a high-value site, like their bank app or even social media account, and keeps both sites open for 10 minutes or so. The attack script runs in the background, attempting to brute-force the active session cookie. If the attack succeeds, an attacker could hijack the session and impersonate the user until the legitimate user logged out.
Mitigating the BEAST
News of the exploit prompted a scramble to mitigate the threat, both on the server side and in browsers. Blocking anything older than the secure TLS 1.1 or TLS 1.2 versions was not an option as nearly all websites and major browsers only supported TLS 1.0 as the highest version of the SSL protocol. For a time, Google Chrome, Mozilla Firefox, and Safari for Mac OS X 10.7 (or earlier) were all vulnerable, as was Internet Explorer on Microsoft Windows XP.
Until a global upgrade to TLS 1.1 was possible, several other mitigations were explored:
- Switch to a stream cipher: The vulnerability only affected block ciphers, so initially the recommended workaround was to switch to a stream cipher also supported in TLS 1.0—the RC4 cipher. Unfortunately, in 2013, RC4 was also found to be insecure, and by 2015 the IETF officially forbade the use of RC4 in any TLS implementation.
- Change the block cipher mode: BEAST only worked in CBC mode, so changing the block cipher mode would have solved the problem—except that TLS 1.0 only supported CBC, eliminating this potential workaround.
- Insert empty packets to use up unsafe initialization vectors: A quick fix was developed that used additional empty packets with zero-length data. Any incomplete block is padded with random data before encryption, so sending a zero-length data block would generate a full block of random padding. Inserted between messages, this new random block serves as the initialization vector for the next message, making encryption secure again. In practice, this fix caused compatibility issues with some SSL stacks, and while implemented in OpenSSL, it was disabled by default.
- Use 1/n-1 packet splitting: Browsers like Firefox and Safari modified their TLS 1.0 implementations to split HTTPS packets without resorting to zero-length data blocks. At the start of each message, you send the first byte of an n-byte data block in a separate packet and put the remaining (that is n-1) bytes of this block in a second packet (hence the name 1/n-1 splitting). The first packet will be padded with random data before being combined with the insecure initialization vector, restoring randomness to the encryption process.
Aftermath of the BEAST
TLS versions older than v1.2 have been deprecated in browsers for many years, so BEAST and similar attacks are no longer a practical threat. Of course, this only applies to modern web browsers and operating systems—it’s not impossible that some vulnerable legacy web applications linger on in ancient company intranets, still running on Windows XP and requiring Internet Explorer 6.0 with some long-obsolete DirectX control or Java applet.
While mostly of historical value, the story of the BEAST attack provides several valuable lessons for security professionals:
- Security protocol implementations often lag behind the latest specifications—when the first BEAST exploit against TLS 1.0 appeared, the vulnerability had already been fixed for five years in the TLS 1.1 specification.
- Cryptographic vulnerabilities considered theoretical or impractical will be practically exploited sooner or later, so it’s good practice to keep up with the latest recommended specifications.
- Even if a cryptographic protocol is theoretically secure, vulnerabilities may be found in its implementations, making it crucial to regularly test your applications for deprecated protocols using an up-to-date vulnerability scanner.
Frequently asked questions
Experience the future of AppSec
