

Warnings about a missing Content-Type header are a common sight in web application scan results. Invicti’s Sven Morgenroth explains how web browsers determine content types and shows how setting the right security headers can get rid of those warnings and eliminate one avenue of cross-site scripting attacks.

If it walks like a duck and quacks like a duck, it’s still not a duck unless it has
an application/duck Content-Type header
Web design was a lot simpler 20 years ago. You had an invisible table over the whole height and width of the page, a few GIF images, and optionally some HTML. There were very few options to make your page stand out, apart from flashy images and choosing a full-page red background color (and the trusty old <blink> tag). And yet, some crafty designers were able to use what they had at hand, invented some clever hacks to bend the clunky old browser features to their will, and actually managed to build some modern-looking, easy-to-navigate websites.
I, on the other hand, don’t possess any of those skills. If you sent me back in time and I had to center a <div> in the middle of the page in 2004, I would probably spend the next four years waiting for Stack Overflow to be invented.
In the present day, all of that has become way easier. You have features like Flexbox and entire CSS frameworks like Bootstrap that do all the heavy lifting for you. Browsers have come a long way since then, adding features that have allowed developers and designers to build web applications with desktop-level functionality. As people adopted them and invented new, creative ways to push the limits of existing solutions, even more features followed, including lots and lots of new data formats—but how do browsers know which format is which?
Hey, what are you looking at?
If you open a modern news site like yahoo.com using the first version of Mozilla Firefox, you will notice some differences compared to what you’re used to, like missing content or the articles not being in the intended order. This is because many browser features we rely on for modern web design weren’t yet invented back in 2004. But on top of that, neither the magnifying glass of the search button nor the Yahoo logo itself are loading. And that’s a bit strange since, of course, images were clearly supported back then.

How the current version of yahoo.com is rendered in Firefox 1.0 from 2004
as compared to a modern Chrome browser
What was not supported, however, was the specific image format Yahoo uses for these buttons. They are not a GIF or JPG but rather an SVG file—an XML-based image format that has some unique advantages but was not yet supported in the first Firefox version. It is one of dozens of file formats added over the years, including image formats such as WEBP. With this ever-increasing number of image file formats that all need to be parsed differently, it can be hard for a browser to figure out what it’s actually looking at.
Sure, you could try going by the specific file extension, such as .png or .jpg, but sometimes these might not be available, like when multiple file types are served from a central endpoint. (For the security implications of this approach, see our post on local file inclusion.) Besides, the browser might not even be looking at an image as such, as with SVG files. SVG is an XML-based image format, so how can the browser be sure it is dealing with an image and not an XML document?
The simple solution to all these problems was to create a dedicated Content-Type header to state the data type upfront.
Meet the Content-Type header
The Content-Type header is a bit like the address on an envelope. To send the data to the right place internally, the browser first needs to read the header value to determine what kind of data it is dealing with. If it says image/png, the browser will try to process a PNG file. If it’s application/xml, it will try to display an XML file. (As a side note, XML has more than one possible Content-Type value: you have text/xml for XML data readable by humans and application/xml for data unreadable for the average user. Personally, I always use application/xml since I have yet to see an XML file that’s easily readable.)
When dealing with static files, your server will often automatically set the Content-Type header for you. To do this, it may deduce the type of content based on the file extension or by actually examining the file. If you’re ever unsure yourself, a great tool for figuring it out is the Linux file utility. Here’s a quick experiment to show how it works:

This example uses curl to download an HTML page from google.com and then saves it locally as a file called google.unknown. We then give that content to the file utility to figure out the content type—which it does, telling us correctly that it’s an HTML document. Smart, but how did it know? We certainly didn’t give it a known extension (in fact, we gave it an .unknown extension). A look at the relevant format definition file from the file utility repo provides the answer:

When examining file content, multiple indicators can suggest that a document is an HTML file. Since some of those are present in the file we downloaded, file knows it’s dealing with an HTML file, and this is one way a web server can automatically set the content type.
How browsers determine the content type
Getting back to browsers, we already know they use the Content-Type header to figure out what kind of file they are dealing with. But what happens if that header is missing? Let’s test it out.
I wrote a simple script that just prints onto the page whatever you put into the message GET parameter:
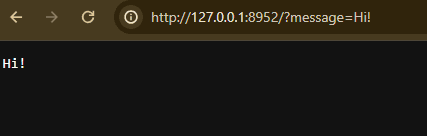
Let’s try to add some HTML content, maybe a red heading for those 2000s vibes:

Even though the Content-Type response header is missing and the request doesn’t mention HTML anywhere, the browser still knows exactly what we are trying to achieve and renders the heading as expected.
Clearly, the browser (like the server) also has ways to automatically detect the content type. When the browser attempts to interpret the media type of an HTTP response by analyzing the response body, this is called MIME sniffing. But did it actually infer the type from the content? Maybe it just defaults to the text/html type? This calls for another experiment.
Let’s take the same string as before and add the characters GIF89a at the beginning:
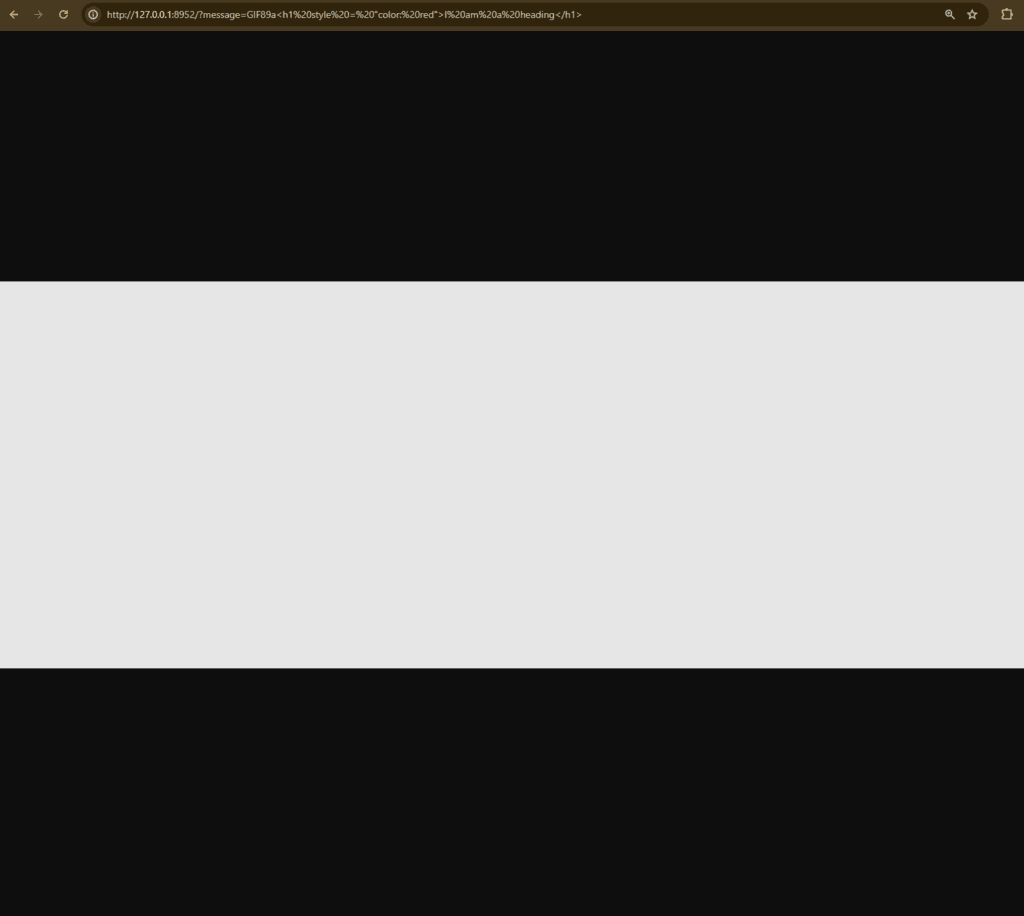
Now, the browser shows a white box instead of HTML content. Let’s save this string under the name box.unknown and give it to our old friend, the file utility, to see what’s going on:

Both file and the browser apparently interpret it as a GIF image now. This is because GIF files always start with the string GIF8, followed by the version (in this case 9a) and then some bytes specifying the length and other data. The weird image size is caused by the browser (and file) interpreting some of the HTML content as size values.
The dangers of uncontrolled sniffing
The weird thing is that, even with the prepended GIF89a characters, this is still all proper and valid HTML. There’s an HTML heading tag, there’s a style attribute, and even the tag content itself insists it’s a heading—and why would it lie to you? But still, browsers interpret it as a GIF.

It’s not hard to imagine how that might go wrong in the other direction. If you let your users upload any data they want and then you serve it without a proper Content-Type header, then—even if you do some upload filtering to ensure a file seems valid—there could still be surprises once served due to browser-side content interpretations.
Of course, there’s also the security side. Depending on where dynamically generated user input is reflected on your page, your browser might be tricked into treating a harmless text file as something more dangerous. If it decides to treat some content as an HTML page, this might be abused to execute client-side JavaScript code within the context of your domain—a long-winded way of saying you are risking cross-site scripting (XSS) attacks.
All this means you should always set a Content-Type header. Stating the correct content type upfront not only helps to ensure the proper functioning of your website but also makes it harder for attackers to trick your browser into performing unintended actions and internally directing input data to the wrong parser. But even assuming you always have the proper Content-Type header set, there is one other security feature you should also enable.
Content-Type alone is not enough
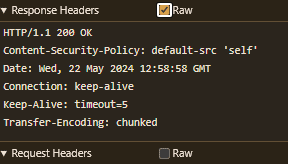
No matter how careful you are, browsers might sometimes straight up ignore your declared content type if they deem it to be wrong. For example, imagine you have a pretty strict Content Security Policy that only allows scripts from the same site to be loaded:
Content-Security-Policy: default-src 'self'
This prevents the browser from loading any external script but allows scripts on the same page. But even if you have a page with a proper Content-Type header that should not normally be interpreted as application/javascript, you might still be out of luck if the page allows dynamic user input.
To see why, let’s assume you are the owner of example.com. An attacker could simply use a script block such as the following to bypass your CSP directive:
<script src = "https://example.com/api/message?data=alert(1)//"></script>
Even if the message API endpoint only returns data as text/plain, this will still lead to XSS because the browser is trying to be smarter than you. In this case, the browser assumes the Content-Type header is incorrect because it’s being used in the context of a script include, which you would only want to do if the data you’re including is actually a JavaScript file. Based on this, the browser decides it knows better, ignores the text/plain type, and treats the request like application/javascript.
The solution to this problem is to not only explicitly state the Content-Type header value but also to disable MIME sniffing by setting the X-Content-Type-Options: nosniff HTTP header. This will leave no room for creative interpretation by the browser and CSP bypasses like the one above will no longer allow attackers to inject potentially malicious code.
X-Content-Type-Options is only one of several HTTP response headers that are essential for security. Read our white paper on HTTP security headers to get the full picture.
Never trust a browser with your content types
In summary, it’s never a good idea to allow the browser to decide the content type based on MIME type sniffing. For secure and predictable behavior, always ensure both of the following are done:
- Explicitly set the expected
Content-Typeheader value for each resource you are serving. - Always set the
X-Content-Type-Optionsheader tonosniffto prevent sniffing when a browser decides to ignore your declared content type.
While they might not be clear and exploitable vulnerabilities, it’s always worth paying attention to scanner warnings related to missing Content-Type and X-Content-Type-Options headers as part of basic security hygiene. On top of that, if your data includes user-controlled input, make sure you perform validation to ensure it is always escaped properly and, where appropriate, assign it a content type that cannot be used to execute JavaScript code.