Brainstorm tool release: Optimizing web fuzzing with local LLMs


This article introduces brainstorm: a smarter web fuzzing tool that combines local LLM models and ffuf to optimize directory and file discovery.

Introducing brainstorm
Brainstorm is a web fuzzing tool that combines local LLM models and ffuf to optimize directory and file discovery. It combines traditional web fuzzing techniques (as implemented in ffuf) with AI-powered path generation to discover hidden endpoints, files, and directories in web applications. brainstorm usually finds more endpoints with fewer requests.
The tool is available here:
https://github.com/Invicti-Security/brainstorm
ffuf
ffuf is one of the most popular tools for performing web fuzzing and is my favorite tool for such tasks. It's an excellent tool, fast, easy to use and very configurable.
Ollama
Ollama is a tool for running open LLMs (Large Language Models) locally. You can run models such as Llama 3.2, Phi 3, Mistral, Gemma 2, Qwen 2.5 coder and other models on your own machine without having to pay anything. It's available for macOS, Linux, and Windows.
How brainstorm works
brainstorm works by generating intelligent guesses for potential paths and filenames based on some initial links extracted from the target website. It works by:
- Extracting initial links from the target website
- Using AI (local LLM models) to analyze the structure and suggest new potential paths
- Fuzzing these paths using ffuf
- Learning from discoveries to generate more targeted suggestions
- Repeating the whole process
Example of running brainstorm
Say that we have a website that has two files: index.php and login.php.
Manually, we would run a local Ollama model such as qwen2.5-coder using the following command:
ollama run qwen2.5-coder
(if you don't have qwen2.5 coder on your machine you would need to download it first using ollama pull qwen2.5-coder)
We would then paste a very long prompt where we ask the LLM to brainstorm new potential filenames or directories, you can find the full prompt here.
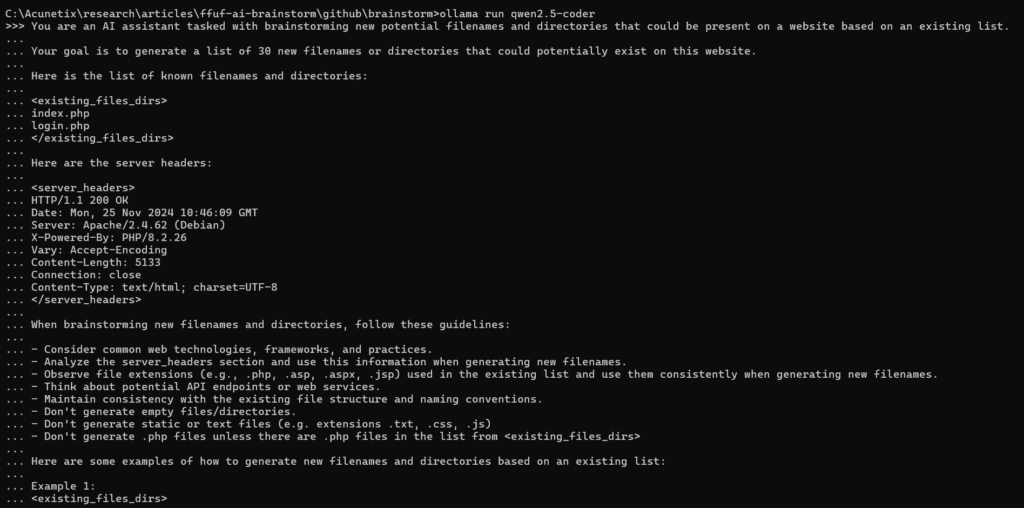
qwen answered with the following list of potential files based on the original files (index.php and login.php).
<new_files_dirs>
dashboard.php
profile.php
settings.php
help.php
terms.php
privacy.php
contact.php
about.php
blog.php
articles.php
posts.php
comments.php
gallery.php
images.php
videos.php
audio.php
downloads.php
store/index.php
store/list.php
store/view.php
store/cart.php
store/checkout.php
store/payment.php
api/v1/users
api/v1/orders
api/v1/products
api/v1/categories
api/v1/tags
api/v1/comments
api/v2/users
api/v2/orders
api/v2/products
api/v2/categories
api/v2/tags
api/v2/comments
admin/index.php
admin/login.php
admin/logout.php
admin/dashboard.php
admin/users.php
admin/settings.php
admin/logs.php
</new_files_dirs>
Not bad, some of the suggestions are pretty good and of course you can modify the prompt to include different guidelines for your specific case (to generate different types of filenames, directories, APIs, etc.)
Another important thing to know is that LLMs have non-deterministic behavior, meaning that if you ask the same question again you might receive different answers (different filenames). We could use this behavior in our favor to generate other potential filenames and directories.
This is the basic gist of how brainstorm work: it automates the whole process above using the Ollama API. From the original links, it generates new potential links, test them using ffuf, if it finds new filenames that are valid, it adds them to the prompt, and then repeats everything many times.
Trying out brainstorm and ffuf on a test website
To test this tool, I've built a test website using links from a real website (from a bug bounty program). This test website is an older Java website with .jsp files. This website has two links on the main page: index.jsp and userLogin.jsp.
Using ffuf with fuzz.txt
Let's fuzz this website with a very good wordlist that I use a lot in my tests: fuzz.txt. It is maintained by Bo0oM and it's an excellent wordlist, I highly recommend it.

It found only one endpoint: api. That's to be expected, as fuzz.txt is not designed for .jsp files. Let's try with a .jsp specific wordlist.
Using ffuf with jsp.txt
Next, we will use a .jsp specific wordlist, this is part of a collection of tech-specific wordlists. The wordlist is jsp.txt. It contains 100,000 jsp specific files.

Much better, it found 5 endpoints—but it made 100,000 requests to the target website.
Using brainstorm
Now, let's use the new tool, brainstorm. It is designed to receive a full ffuf command line as a command line argument, so you can run ffuf first, exclude some responses, and then pass the full command line to brainstorm.

In the first cycles, it found some interesting files such as forgotPassword.jsp, about.jsp, cart.jsp, checkout.jsp, contact.jsp and after a few more cycles it found other files such as userRegister.jsp. This last one is interesting because it was brainstormed from the initial link userLogin.jsp. Some API endpoints were also found.

After a while, no new files were found, so I stopped the process.
In the end, a total of 10 new endpoints were discovered BUT we only sent 328 requests. That's much better when compared with the jsp.txt wordlist where we found 5 endpoints but sent 100,000 requests. Also, we did not send all the requests at once, we sent 30 requests, waited until the LLM generated more possible filenames and then sent a few more requests (only the new/unique filenames). This is important because if you send 100,000 requests at once most websites will block you immediately but if you send a few requests from time to time this might get under the radar.
ToolNumber of requestsEndpoints foundffuf with wordlist fuzz.txt53391ffuf with wordlist jsp.txt1000005brainstorm32810
Comparison between ffuf with wordlists and brainstorm
Which LLM model to use?
As you've probably noticed above, I'm using the model qwen2.5-coder by default, I like the qwen models a lot and use them daily, I consider them the best local models available right now.
But I wanted to check maybe other models are better on this specific task. So, I wrote a python script to test all the models that I had installed on my computer and check how many endpoints each one found.
The models that I've tested are:
ModelCompanyParametersmistralMistral AI7Bllama3.1Meta8Bllama3.2Meta3Bqwen2.5Alibaba7Bqwen2.5-coderAlibaba7Bqwen2.5-coder:14bAlibaba14BgemmaGoogle7Bphi3Microsoft3.8B
Models tested
Some models are bigger (like qwen2.5-coder:14b with 14B) and others smaller (phi3 with 3.8B)—these are simply the models I had on my machine.
In the end, the results are as follows:

As expected, the bigger models (14B) perform better but from the 7/8B parameter models the qwen models are usually pretty good. llama3.1 as also doing very well. You can find the full benchmark results here.
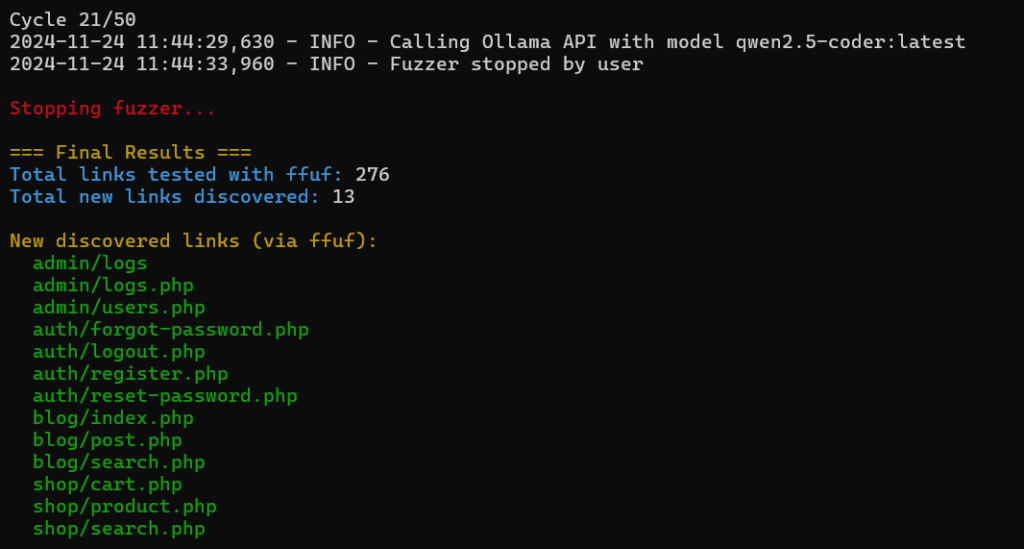
Another test website (PHP)
I tested brainstorm with another test website, this time PHP-based. It started with one file auth/login.php and it discovered 13 new endpoints while making 276 requests.
Shortname scanner
The idea behind this tool could be applied to other fuzzing problems. It could be applied for fuzzing APIs, subdomains, virtual hosts, ...
As an example, I will show how I applied this idea to fuzzing IIS short (8.3) filenames. IIS (Internet Information Services) uses short (8.3) filenames, a legacy feature from older file systems like FAT, to maintain compatibility with applications that require 8-character filenames and 3-character extensions. These short names are automatically created by the file system for files and directories with long names.
There are well known IIS short (8.3) filenames scanners such as IIS-ShortName-Scanner from Soroush Dalili. These tools take advantage of a vulnerability in IIS that allows attackers to enumerate short filenames. But once you have a short filename such as FORGOT~1.JSP you need a way to guess the full filename. As an example, the full name behind this short filename is forgotPassword.jsp.
I've adapted the original script fuzzer.py to try to guess full names when provided with a short filename. The new script is fuzzer_shortname.py. You provide this script with ffuf command line and with a short filename and the LLM will try to brainstorm full filenames.
The LLM prompt that I've used in this case is available here.
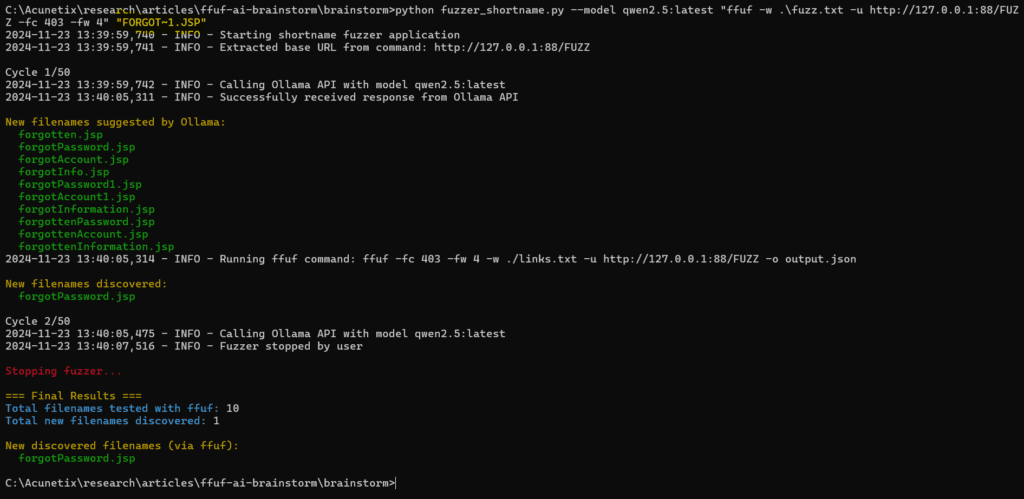
As you can see above, the new filenames suggested are pretty good and the tool was able to identify the correct full filename.
However, it does not work as well in all cases. LLMs sometimes suggest filenames that don't start with the short filename even if the prompt includes the following requirement: "All the filenames should start with the filename before the tilde and use the same extension. DO NOT generate filenames that don't start with the filename before the tilde or use a different extension."

As you can see above, filenames like userReset.jsp were suggested even if the short filename is FORGOT~1.JSP. This is a known limitation of local LLMs, it doesn't apply to bigger LLMs. I'm not aware of a solution to this problem except switching to bigger LLMs.
Conclusion
I think that future fuzzing tools should be rewritten to take advantage of the benefits that LLMs provide. LLMs are great at brainstorming new items, and I hope this idea will next be applied to improving subdomain discovery, where you provide the LLM with a list of identified subdomains and ask it to generate variations based on those existing subdomains. The LLM should be able to identify patterns in the found subdomains and brainstorm new subdomains using the patterns it found.
Bigger LLMs are better
Also, this tool is designed to use local LLMs (with sizes of 7/8B and 14B) that you can run on your local computer without having to pay for access. I've experimented with smarter LLMs such as Claude Sonnet 3.5 and the results are much better, but it costs money to run the tool, so it might not make sense in all cases.
Frequently asked questions
Experience the future of AppSec
